
La Technique du Shadowing est un exercice de prononciation de haute intensité où vous écoutez un discours natif et le répétez à voix haute avec un délai de 0,5 seconde — en « suivant comme une ombre » (shadowing) le locuteur. Contrairement à la répétition standard (écouter, pause, répéter), le shadowing force votre cerveau à traiter l'intonation, la vitesse et le rythme en temps réel. Cependant, pour que cette technique améliore réellement votre accent, vous devez inclure un « Diff Check » — une boucle de rétroaction par enregistrement pour identifier où votre sortie s'écarte de la source.
L'erreur « Ça marche sur ma machine »
Nous sommes tous passés par là. Vous pratiquez une phrase seul dans votre chambre. Elle sonne parfaitement. Vous vous sentez confiant. Ensuite, vous la dites à un locuteur natif, et il fronce les sourcils. « Quoi ? »
Vous venez de vivre un échec de déploiement classique. En génie logiciel, nous appelons cela le problème « Ça marche sur ma machine » (Works on My Machine). Le code fonctionne bien dans votre environnement local (votre tête), mais plante en production (l'oreille de l'auditeur).
Pourquoi cela arrive-t-il ? C'est dû à un biais cognitif appelé la Boucle Phonologique. Votre cerveau est un auto-correcteur agressif. Lorsque vous parlez, votre cerveau anticipe le son que vous avez l'intention de produire et « entend » cette intention, filtrant vos erreurs réelles. Vous ne pouvez littéralement pas entendre votre propre accent parce que vos « tests unitaires » internes sont biaisés.
Pour corriger votre prononciation, vous devez arrêter de compter sur vos capteurs internes et commencer à regarder les journaux d'erreurs (logs).
L'Algorithme de Shadowing (Protocole Manuel)
Le moyen le plus efficace de contourner la boucle phonologique est le Shadowing. Ce n'est pas juste « répéter après le professeur ». C'est une tâche de traitement synchrone. Voici l'algorithme pour une session de Shadowing correcte :
- Flux d'entrée (Input Stream) : Trouvez un audio natif (un podcast, un extrait d'actualités ou un dialogue) avec une transcription.
- Configuration de la latence : Lancez l'audio. N'attendez pas la fin de la phrase.
- Traitement : Commencez à parler au moment où l'audio commence, en restant environ 0,5 seconde derrière le locuteur.
- Synchronisation : Imitez la musique, pas seulement les mots. Si le locuteur accélère, vous accélérez. S'il monte dans les aigus, vous montez aussi.
Avertissement : C'est cognitivement coûteux. Cela consomme une grande bande passante mentale. Mais cela seul ne suffit pas. Vous exécutez toujours le code sans vérifier la sortie.
Le « Diff Check » : Pourquoi vous avez besoin d'une boucle de rétroaction
La recherche sur l'hypothèse du noticing (Noticing Hypothesis) suggère que les apprenants ne corrigent les erreurs que lorsqu'ils remarquent consciemment l'écart entre leur production et l'entrée cible. Si vous faites du shadowing sans vous enregistrer, vous écrivez du code sans compilateur. Vous vous sentez productif, mais vous renforcez probablement des bugs.
Pour déboguer efficacement votre prononciation, vous devez effectuer un Diff Check :
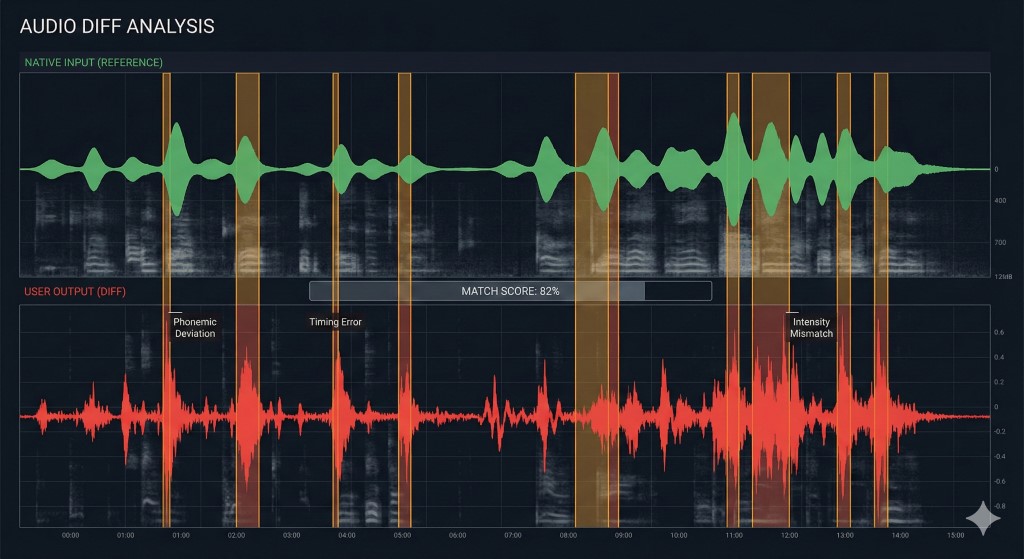
| Étape | Action | Équivalent « Ingénierie » |
|---|---|---|
| 1. Enregistrer | Enregistrez votre voix pendant le shadowing de l'audio natif. | > capture logs |
| 2. Superposer | Écoutez votre enregistrement immédiatement après l'audio natif. | > git diff |
| 3. Identifier | Marquez exactement où votre rythme ou vos voyelles ont dévié. | > bug triage |
| 4. Corriger (Patch) | Répétez le segment spécifique jusqu'à ce que le « diff » soit nul. | > hotfix |
Lecture connexe : Si vous constatez que vos erreurs sont grammaticales plutôt que phonétiques, consultez notre guide sur le Refactoring de votre grammaire pour corriger les erreurs de syntaxe fossilisées.
Automatiser le débogueur avec DialogoVivo
Le protocole manuel ci-dessus est efficace, mais fastidieux. Configurer des appareils d'enregistrement, mettre en pause l'audio et parcourir les timelines ajoute une friction massive. Lorsque la friction est élevée, vous arrêtez de pratiquer.
C'est pourquoi nous avons créé DialogoVivo. Nous voulions automatiser le « Diff Check » et transformer la pratique de la prononciation en une session de débogage rationalisée.
Nous avons conçu l'application avec deux modes distincts pour agir comme votre boucle de rétroaction objective :
- Mode Natif : Utilise le SpeechRecognizer interne d'Android. Pensez-y comme à un « Compilateur » strict. Il ne se soucie pas de vos sentiments. Si votre prononciation d'un phonème spécifique est incorrecte, le reconnaisseur transcrira le mauvais mot. Cela vous force à parler suffisamment clairement pour qu'une machine comprenne — si l'IA ne peut pas l'analyser, un humain ne le pourra probablement pas non plus.
- Mode API : Pour une analyse plus approfondie, ce mode utilise des services de transcription backend (comme Whisper) pour capturer les nuances.
Au lieu de gérer vous-même les fichiers audio, DialogoVivo exécute la boucle pour vous :
- Le Scénario : Vous entrez dans un jeu de rôle (par exemple, « Commander un café »).
- L'Entrée : L'IA prononce une phrase native.
- La Sortie : Vous répondez. L'application vous enregistre et vous transcrit instantanément.
- Le journal d'erreurs : Si vous prononcez mal un mot au point de changer le sens, l'Agent de Validation le signale immédiatement, vous montrant exactement ce que « l'auditeur » a entendu par rapport à ce que vous vouliez dire.
Arrêtez de déployer du code buggé
Vous n'avez pas besoin d'avoir un accent « parfait », mais vous avez besoin d'une parole claire et exécutable. Si vous en avez assez d'être mal compris, vous devez arrêter de faire confiance à vos oreilles et commencer à faire confiance aux données.
Vous pouvez essayer la technique manuelle de Shadowing dès aujourd'hui avec n'importe quel podcast. Ou, si vous voulez un bac à sable automatisé pour tester votre prononciation avant de parler à de vrais humains, vous pouvez télécharger DialogoVivo sur Android.
Traitez votre parole comme du code : auditez-la, déboguez-la, puis déployez-la en toute confiance.