
La Técnica de Shadowing (Sombreado) es un ejercicio de pronunciación de alta intensidad en el que escuchas el habla nativa y la repites en voz alta con un retraso de 0,5 segundos, efectivamente haciendo de "sombra" al hablante. A diferencia de la repetición estándar (escuchar, pausar, repetir), el shadowing obliga a tu cerebro a procesar la entonación, la velocidad y el ritmo en tiempo real. Sin embargo, para que esta técnica mejore realmente tu acento, debes incluir un "Diff Check": un bucle de retroalimentación de grabación para identificar dónde se desvía tu salida de la fuente.
La falacia de "En mi máquina funciona"
Todos hemos pasado por eso. Practicas una frase solo en tu habitación. Suena perfecta. Te sientes seguro. Luego, se la dices a un hablante nativo y frunce el ceño. "¿Qué?"
Acabas de experimentar un fallo de despliegue (deployment failure) clásico. En ingeniería de software, llamamos a esto el problema de "En mi máquina funciona" (Works on My Machine). El código se ejecuta bien en tu entorno local (tu cabeza), pero falla en producción (el oído del oyente).
¿Por qué sucede esto? Se debe a un sesgo cognitivo llamado Bucle Fonológico. Tu cerebro es un autocorrector agresivo. Cuando hablas, tu cerebro anticipa el sonido que pretendes hacer y "oye" esa intención, filtrando tus errores reales. Literalmente no puedes escuchar tu propio acento porque tus "pruebas unitarias" internas están sesgadas.
Para arreglar tu pronunciación, necesitas dejar de confiar en tus sensores internos y empezar a mirar los registros de errores (error logs).
El Algoritmo de Shadowing (Protocolo Manual)
La forma más efectiva de evitar el Bucle Fonológico es el Shadowing. Esto no es solo "repetir después del profesor". Es una tarea de procesamiento síncrono. Aquí está el algoritmo para una sesión de Shadowing adecuada:
- Flujo de entrada (Input Stream): Encuentra audio nativo (un podcast, un clip de noticias o un diálogo) con una transcripción.
- Configuración de latencia: Inicia el audio. No esperes a que termine la frase.
- Procesamiento: Comienza a hablar en el momento en que comienza el audio, yendo unos 0,5 segundos por detrás del hablante.
- Sincronización: Imita la música, no solo las palabras. Si el hablante acelera, tú aceleras. Si sube el tono, tú subes el tuyo.
Advertencia: Esto es cognitivamente costoso. Consume un gran ancho de banda mental. Pero esto por sí solo no es suficiente. Todavía estás ejecutando el código sin verificar la salida.
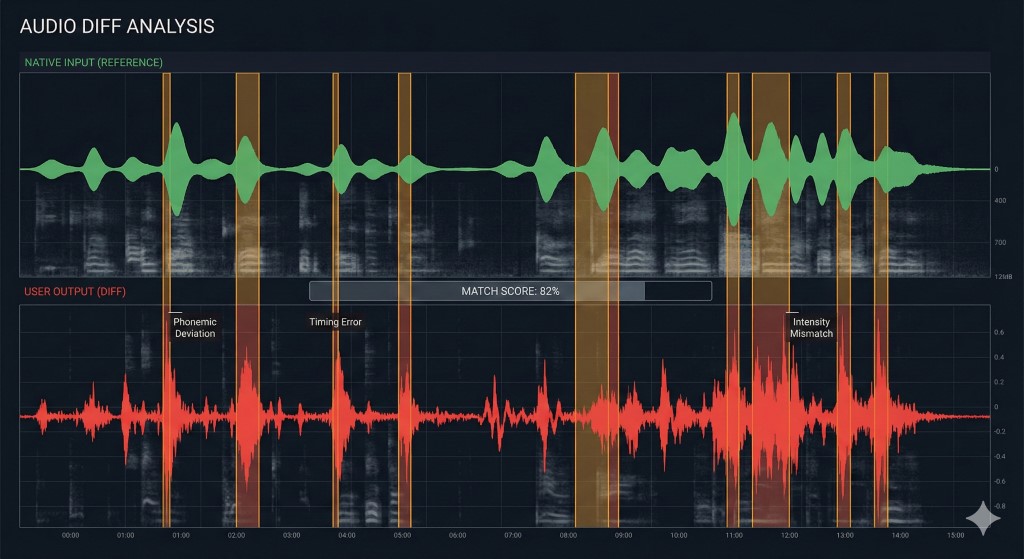
El "Diff Check": Por qué necesitas un bucle de retroalimentación
La investigación sobre la Hipótesis de Notación (Noticing Hypothesis) sugiere que los estudiantes solo corrigen errores cuando notan conscientemente la brecha entre su salida y la entrada objetivo. Si haces shadowing sin grabarte, estás escribiendo código sin un compilador. Te sientes productivo, pero probablemente estás reforzando errores (bugs).
Para depurar tu pronunciación de manera efectiva, debes realizar un Diff Check:
| Paso | Acción | Equivalente de "Ingeniería" |
|---|---|---|
| 1. Grabar | Graba tu voz mientras haces shadowing del audio nativo. | > capture logs |
| 2. Superponer | Escucha tu grabación inmediatamente después del audio nativo. | > git diff |
| 3. Identificar | Marca exactamente dónde se desviaron tu ritmo o los sonidos de las vocales. | > bug triage |
| 4. Parchear | Repite el segmento específico hasta que el "diff" sea cero. | > hotfix |
Lectura relacionada: Si encuentras que tus errores son gramaticales en lugar de fonéticos, consulta nuestra guía sobre Refactorización de tu Gramática para corregir errores de sintaxis fosilizados.
Automatizando el Depurador con DialogoVivo
El protocolo manual anterior es efectivo, pero es tedioso. Configurar dispositivos de grabación, pausar el audio y desplazarse por las líneas de tiempo agrega una fricción masiva. Cuando la fricción es alta, dejas de practicar.
Es por eso que construimos DialogoVivo. Queríamos automatizar el "Diff Check" y convertir la práctica de pronunciación en una sesión de depuración optimizada.
Diseñamos la aplicación con dos modos distintos para que actúen como tu bucle de retroalimentación objetivo:
- Modo Nativo: Utiliza el SpeechRecognizer interno del sistema operativo Android. Piensa en esto como un "Compilador" estricto. No le importan tus sentimientos. Si tu pronunciación de un fonema específico es incorrecta, el reconocedor transcribirá la palabra equivocada. Te obliga a hablar lo suficientemente claro para que una máquina te entienda; si la IA no puede analizarlo, es probable que un humano tampoco pueda.
- Modo API: Para un análisis más profundo, este modo utiliza servicios de transcripción backend (como Whisper) para capturar matices.
En lugar de administrar archivos de audio tú mismo, DialogoVivo ejecuta el bucle por ti:
- El Escenario: Entras en un juego de roles (por ejemplo, "Pedir café").
- La Entrada: La IA dice una frase nativa.
- La Salida: Tú respondes. La aplicación te graba y transcribe al instante.
- El Registro de Errores: Si pronuncias mal una palabra tanto que cambia el significado, el Agente de Validación la marca inmediatamente, mostrándote exactamente lo que el "oyente" escuchó frente a lo que querías decir.
Deja de desplegar código con errores
No necesitas tener un acento "perfecto", pero necesitas un habla clara y ejecutable. Si estás cansado de ser malinterpretado, necesitas dejar de confiar en tus oídos y empezar a confiar en los datos.
Puedes probar la técnica manual de Shadowing hoy con cualquier podcast. O, si quieres un entorno de pruebas automatizado para probar tu pronunciación antes de hablar con humanos reales, puedes descargar DialogoVivo en Android.
Trata tu habla como código: audítala, depúrala y luego despliégala con confianza.