
La Tecnica dello Shadowing è un esercizio di pronuncia ad alta intensità in cui ascolti un discorso nativo e lo ripeti ad alta voce con un ritardo di 0,5 secondi, facendo effettivamente da "ombra" all'oratore. A differenza della ripetizione standard (ascolta, pausa, ripeti), lo shadowing costringe il tuo cervello a elaborare intonazione, velocità e ritmo in tempo reale. Tuttavia, affinché questa tecnica migliori effettivamente il tuo accento, devi includere un "Diff Check", un ciclo di feedback di registrazione per identificare dove il tuo output devia dalla fonte.
La fallacia di "Sulla mia macchina funziona"
Ci siamo passati tutti. Ti eserciti con una frase da solo in camera tua. Suona perfetta. Ti senti sicuro. Poi, la dici a un madrelingua e lui aggrotta le sopracciglia. "Cosa?"
Hai appena sperimentato un classico fallimento di distribuzione (deployment failure). Nell'ingegneria del software, chiamiamo questo il problema "Works on My Machine" (Funziona sulla mia macchina). Il codice funziona bene nel tuo ambiente locale (la tua testa), ma va in crash in produzione (l'orecchio dell'ascoltatore).
Perché succede questo? È dovuto a un bias cognitivo chiamato Loop Fonologico. Il tuo cervello è un correttore automatico aggressivo. Quando parli, il tuo cervello anticipa il suono che intendi produrre e "sente" quell'intenzione, filtrando i tuoi errori reali. Letteralmente non puoi sentire il tuo accento perché i tuoi "unit test" interni sono parziali.
Per correggere la tua pronuncia, devi smettere di fare affidamento sui tuoi sensori interni e iniziare a guardare i log degli errori.
L'algoritmo di Shadowing (Protocollo manuale)
Il modo più efficace per bypassare il Loop Fonologico è lo Shadowing. Questo non è solo "ripetere dopo l'insegnante". È un compito di elaborazione sincrona. Ecco l'algoritmo per una corretta sessione di Shadowing:
- Input Stream: Trova audio nativo (un podcast, un notiziario o un dialogo) con una trascrizione.
- Setup latenza: Avvia l'audio. Non aspettare che la frase finisca.
- Elaborazione: Inizia a parlare nel momento in cui inizia l'audio, rimanendo circa 0,5 secondi dietro l'oratore.
- Sincronizzazione: Imita la musica, non solo le parole. Se l'oratore accelera, tu acceleri. Se alza il tono, tu alzi il tuo.
Attenzione: Questo è cognitivamente costoso. Consuma un'elevata larghezza di banda mentale. Ma questo da solo non basta. Stai ancora eseguendo il codice senza controllare l'output.
Il "Diff Check": Perché hai bisogno di un ciclo di feedback
La ricerca sull'Ipotesi dell'Attenzione (Noticing Hypothesis) suggerisce che gli studenti correggono gli errori solo quando notano consapevolmente il divario tra il loro output e l'input target. Se fai shadowing senza registrarti, stai scrivendo codice senza un compilatore. Ti senti produttivo, ma probabilmente stai rinforzando i bug.
Per debuggare la tua pronuncia in modo efficace, devi eseguire un Diff Check:
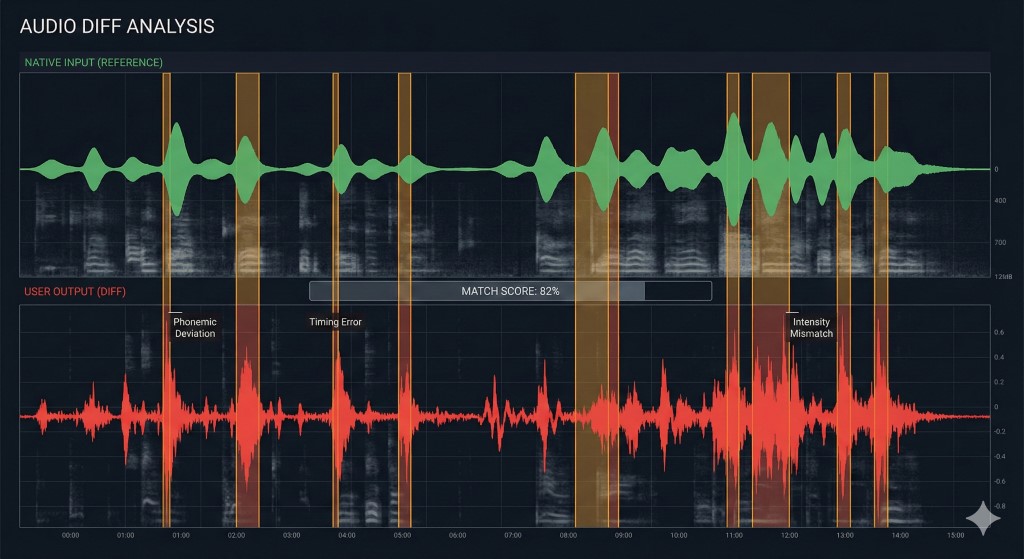
| Passo | Azione | Equivalente "Ingegneristico" |
|---|---|---|
| 1. Registra | Registra la tua voce mentre fai shadowing dell'audio nativo. | > capture logs |
| 2. Sovrapponi | Ascolta la tua registrazione immediatamente dopo l'audio nativo. | > git diff |
| 3. Identifica | Segna esattamente dove il tuo ritmo o le vocali hanno deviato. | > bug triage |
| 4. Patch | Ripeti il segmento specifico finché il "diff" non è zero. | > hotfix |
Lettura correlata: Se scopri che i tuoi errori sono grammaticali piuttosto che fonetici, dai un'occhiata alla nostra guida sul Refactoring della tua Grammatica per correggere errori di sintassi fossilizzati.
Automatizzare il debugger con DialogoVivo
Il protocollo manuale sopra descritto è efficace, ma è noioso. Impostare dispositivi di registrazione, mettere in pausa l'audio e scorrere le timeline aggiunge un enorme attrito. Quando l'attrito è alto, smetti di esercitarti.
Ecco perché abbiamo creato DialogoVivo. Volevamo automatizzare il "Diff Check" e trasformare la pratica della pronuncia in una sessione di debugging ottimizzata.
Abbiamo progettato l'app con due modalità distinte per agire come il tuo ciclo di feedback oggettivo:
- Modalità Nativa: Utilizza lo SpeechRecognizer interno del sistema operativo Android. Pensalo come un severo "Compilatore". Non gli importano i tuoi sentimenti. Se la tua pronuncia di uno specifico fonema è sbagliata, il riconoscitore trascriverà la parola sbagliata. Ti costringe a parlare abbastanza chiaramente affinché una macchina capisca: se l'IA non riesce ad analizzarlo, probabilmente nemmeno un umano ci riuscirà.
- Modalità API: Per un'analisi più approfondita, questa modalità utilizza servizi di trascrizione backend (come Whisper) per catturare le sfumature.
Invece di gestire tu stesso i file audio, DialogoVivo esegue il ciclo per te:
- Lo Scenario: Entri in un gioco di ruolo (ad es. "Ordinare un caffè").
- L'Input: L'IA pronuncia una frase nativa.
- L'Output: Tu rispondi. L'app ti registra e ti trascrive istantaneamente.
- Il Log degli Errori: Se pronunci male una parola così tanto da cambiarne il significato, l'Agente di Convalida la segnala immediatamente, mostrandoti esattamente ciò che l'"ascoltatore" ha sentito rispetto a ciò che volevi dire.
Smetti di distribuire codice bacato
Non hai bisogno di avere un accento "perfetto", ma hai bisogno di un discorso chiaro ed eseguibile. Se sei stanco di essere frainteso, devi smettere di fidarti delle tue orecchie e iniziare a fidarti dei dati.
Puoi provare la tecnica manuale di Shadowing oggi con qualsiasi podcast. Oppure, se vuoi una sandbox automatizzata per testare la tua pronuncia prima di parlare con persone reali, puoi scaricare DialogoVivo su Android.
Tratta il tuo discorso come codice: fai audit, debuggalo e poi distribuiscilo con sicurezza.