
シャドーイング(Shadowing)技術は、ネイティブの音声を聴き、0.5秒遅れて声に出して繰り返すという高強度の発音練習法です。話者の「影(シャドー)」になるようなイメージです。標準的なリピート(聞く、一時停止、繰り返す)とは異なり、シャドーイングは脳にイントネーション、スピード、リズムをリアルタイムで処理することを強制します。しかし、この技術で実際にアクセントを改善するには、「Diffチェック(差分確認)」、つまり自分の出力がソースとどこが違うのかを特定するための録音フィードバックループを含める必要があります。
「私の環境では動く(Works on My Machine)」の誤謬
誰もが経験したことがあるでしょう。部屋で一人で文を練習します。完璧に聞こえます。自信があります。そして、ネイティブスピーカーに言ってみると、彼らは眉をひそめます。「え?」
あなたは典型的なデプロイ失敗(deployment failure)を経験したのです。ソフトウェアエンジニアリングでは、これを「私の環境では動く(Works on My Machine)」問題と呼びます。コードはローカル環境(あなたの頭の中)では問題なく動作しますが、本番環境(聞き手の耳)ではクラッシュします。
なぜこれが起こるのでしょうか?それは音韻ループ(Phonological Loop)と呼ばれる認知バイアスによるものです。あなたの脳は攻撃的な自動修正機能を持っています。話すとき、脳はあなたが発しようとする音を予測し、その意図を「聞き」、実際の間違いを除外します。内部の「ユニットテスト」が偏っているため、文字通り自分のアクセントを聞くことができないのです。
発音を直すには、内部センサーに頼るのをやめ、エラーログを見始める必要があります。
シャドーイング・アルゴリズム(手動プロトコル)
音韻ループを回避する最も効果的な方法はシャドーイングです。これは単に「先生の後に続いて繰り返す」ことではありません。同期処理タスクです。適切なシャドーイングセッションのアルゴリズムは次のとおりです。
- 入力ストリーム:トランスクリプト(文字起こし)のあるネイティブ音声(ポッドキャスト、ニュースクリップ、または対話)を見つけます。
- レイテンシ設定:音声を再生します。文が終わるのを待たないでください。
- 処理:音声が始まった瞬間に話し始め、話者の約0.5秒後を追います。
- 同期:単語だけでなく、音楽(リズムや抑揚)を真似します。話者がスピードを上げたら、あなたも上げます。ピッチを上げたら、あなたも上げます。
警告:これは認知的に高負荷です。高い精神的帯域幅を消費します。しかし、これだけでは十分ではありません。まだ出力を確認せずにコードを実行している状態です。
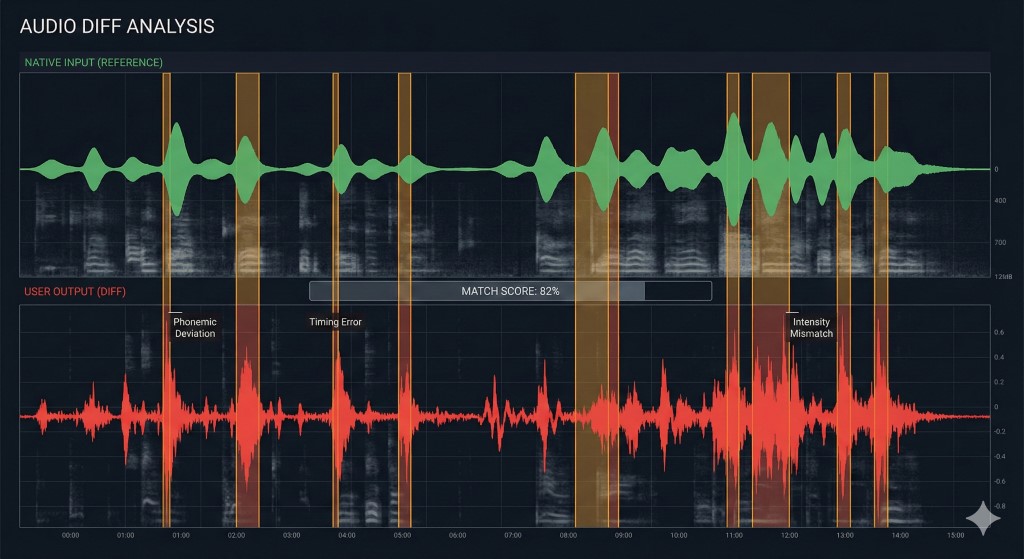
「Diffチェック」:なぜフィードバックループが必要なのか
「気づき仮説(Noticing Hypothesis)」の研究によると、学習者は自分の出力とターゲット入力の間のギャップを意識的に気づいたときにのみエラーを修正します。自分を録音せずにシャドーイングを行うと、コンパイラなしでコードを書いていることになります。生産的だと感じますが、バグを強化している可能性があります。
発音を効果的にデバッグするには、Diffチェックを実行する必要があります。
| ステップ | アクション | 「エンジニアリング」での同等物 |
|---|---|---|
| 1. 録音 | ネイティブ音声をシャドーイングしながら自分の声を録音します。 | > capture logs |
| 2. オーバーレイ | ネイティブ音声の直後に自分の録音を聞きます。 | > git diff |
| 3. 特定 | リズムや母音がずれている箇所を正確にマークします。 | > bug triage |
| 4. パッチ | 「diff(差分)」がゼロになるまで特定のセグメントを繰り返します。 | > hotfix |
関連資料:エラーが音声的ではなく文法的なものであるとわかった場合は、化石化した構文エラーを修正するための文法のリファクタリングに関するガイドをご覧ください。
DialogoVivoによるデバッガの自動化
上記の手動プロトコルは効果的ですが、面倒です。録音デバイスのセットアップ、音声の一時停止、タイムラインの操作は大きな摩擦(手間)を加えます。摩擦が大きいと、練習をやめてしまいます。
これが私たちがDialogoVivoを作った理由です。「Diffチェック」を自動化し、発音練習を合理化されたデバッグセッションに変えたいと考えました。
客観的なフィードバックループとして機能する2つの異なるモードでアプリを設計しました。
- ネイティブモード:Android OS内部のSpeechRecognizerを利用します。これを厳格な「コンパイラ」と考えてください。あなたの感情は気にしません。特定の音素の発音がずれている場合、認識機能は間違った単語を書き起こします。これにより、機械が理解できるほど十分に明確に話すことが強制されます。AIが解析できなければ、人間もおそらく解析できません。
- APIモード:より深い分析のために、このモードではバックエンドの文字起こしサービス(Whisperなど)を使用してニュアンスを捉えます。
自分でオーディオファイルを管理する代わりに、DialogoVivoがループを実行します。
- シナリオ:ロールプレイに入ります(例:「コーヒーを注文する」)。
- 入力:AIがネイティブの文を話します。
- 出力:あなたが応答します。アプリは即座にあなたを録音し、文字起こしします。
- エラーログ:意味が変わるほど単語の発音が悪い場合、検証エージェントがすぐにフラグを立て、「聞き手」が聞いた内容とあなたが言おうとした内容を正確に表示します。
バグのあるコードのデプロイをやめる
「完璧な」アクセントを持つ必要はありませんが、明確で実行可能な話し方は必要です。誤解されることにうんざりしているなら、自分の耳を信じるのをやめ、データを信じ始める必要があります。
今日からどのポッドキャストでも手動のシャドーイング技術を試すことができます。あるいは、実際の人間と話す前に発音をテストするための自動化されたサンドボックスが必要な場合は、AndroidでDialogoVivoをダウンロードできます。
自分の話し方をコードのように扱ってください。監査し、デバッグし、そして自信を持ってデプロイしましょう。