
Die Shadowing-Technik ist eine hochintensive Ausspracheübung, bei der Sie Muttersprachlern zuhören und das Gehörte mit einer Verzögerung von 0,5 Sekunden laut wiederholen – Sie „beschatten“ (shadow) den Sprecher also quasi. Im Gegensatz zur Standardwiederholung (zuhören, pausieren, wiederholen) zwingt Shadowing Ihr Gehirn dazu, Intonation, Geschwindigkeit und Rhythmus in Echtzeit zu verarbeiten. Damit diese Technik jedoch Ihren Akzent tatsächlich verbessert, müssen Sie einen „Diff Check“ einbauen – eine Feedback-Schleife mit Aufnahme, um zu identifizieren, wo Ihr Output von der Quelle abweicht.
Der Irrtum „Funktioniert auf meinem Rechner“
Wir alle kennen das. Sie üben einen Satz allein in Ihrem Zimmer. Er klingt perfekt. Sie fühlen sich sicher. Dann sagen Sie ihn zu einem Muttersprachler, und der runzelt die Stirn. „Wie bitte?“
Sie haben gerade einen klassischen Deployment-Fehler erlebt. In der Softwareentwicklung nennen wir das das Problem „Works on My Machine“ (Funktioniert auf meinem Rechner). Der Code läuft in Ihrer lokalen Umgebung (Ihrem Kopf) einwandfrei, stürzt aber in der Produktion (dem Ohr des Zuhörers) ab.
Warum passiert das? Es liegt an einer kognitiven Verzerrung namens Phonologische Schleife. Ihr Gehirn ist eine aggressive Autokorrektur. Wenn Sie sprechen, antizipiert Ihr Gehirn den Ton, den Sie erzeugen wollen, und „hört“ diese Absicht, wobei Ihre tatsächlichen Fehler herausgefiltert werden. Sie können Ihren eigenen Akzent buchstäblich nicht hören, weil Ihre internen „Unit-Tests“ voreingenommen sind.
Um Ihre Aussprache zu korrigieren, müssen Sie aufhören, sich auf Ihre internen Sensoren zu verlassen, und anfangen, die Fehlerprotokolle (Error Logs) zu betrachten.
Der Shadowing-Algorithmus (Manuelles Protokoll)
Der effektivste Weg, die phonologische Schleife zu umgehen, ist Shadowing. Das ist nicht nur „Nachsprechen“. Es ist eine synchrone Verarbeitungsaufgabe. Hier ist der Algorithmus für eine richtige Shadowing-Sitzung:
- Input Stream: Finden Sie natives Audio (einen Podcast, Nachrichtenclip oder Dialog) mit Transkript.
- Latenz-Setup: Starten Sie das Audio. Warten Sie nicht, bis der Satz zu Ende ist.
- Verarbeitung: Beginnen Sie zu sprechen, sobald das Audio startet, und bleiben Sie etwa 0,5 Sekunden hinter dem Sprecher.
- Synchronisierung: Ahmen Sie die Musik nach, nicht nur die Worte. Wenn der Sprecher schneller wird, werden Sie schneller. Wenn die Tonhöhe steigt, steigen Sie mit.
Warnung: Dies ist kognitiv aufwendig. Es verbraucht viel mentale Bandbreite. Aber das allein reicht nicht aus. Sie führen den Code immer noch aus, ohne den Output zu überprüfen.
Der „Diff Check“: Warum Sie eine Feedback-Schleife brauchen
Forschungen zur „Noticing Hypothesis“ legen nahe, dass Lernende Fehler nur korrigieren, wenn sie die Lücke zwischen ihrem Output und dem Ziel-Input bewusst wahrnehmen. Wenn Sie Shadowing betreiben, ohne sich aufzunehmen, schreiben Sie Code ohne Compiler. Sie fühlen sich produktiv, aber wahrscheinlich festigen Sie Bugs.
Um Ihre Aussprache effektiv zu debuggen, müssen Sie einen Diff Check durchführen:
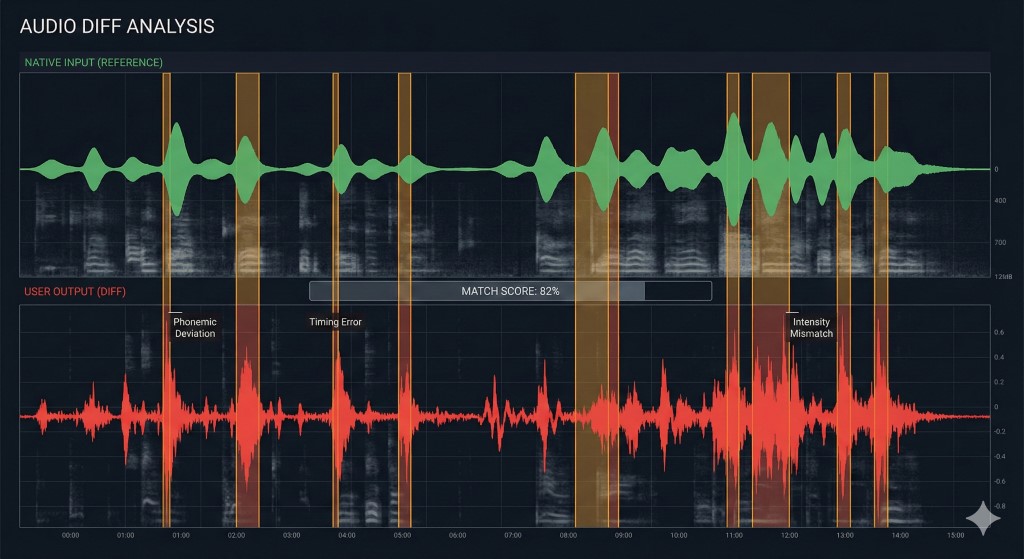
| Schritt | Aktion | „Engineering“-Äquivalent |
|---|---|---|
| 1. Aufnahme | Nehmen Sie Ihre Stimme während des Shadowings auf. | > capture logs |
| 2. Overlay | Hören Sie Ihre Aufnahme sofort nach dem Original-Audio an. | > git diff |
| 3. Identifizieren | Markieren Sie genau, wo Rhythmus oder Vokale abgewichen sind. | > bug triage |
| 4. Patch | Wiederholen Sie das Segment, bis der „Diff“ null ist. | > hotfix |
Weiterführende Lektüre: Wenn Sie feststellen, dass Ihre Fehler eher grammatikalischer als phonetischer Natur sind, schauen Sie sich unseren Leitfaden zum Refactoring Ihrer Grammatik an, um verfestigte Syntaxfehler zu beheben.
Automatisierung des Debuggers mit DialogoVivo
Das obige manuelle Protokoll ist effektiv, aber mühsam. Das Einrichten von Aufnahmegeräten, Pausieren und Zurückspulen erzeugt massive Reibung. Wenn die Reibung hoch ist, hören Sie auf zu üben.
Deshalb haben wir DialogoVivo gebaut. Wir wollten den „Diff Check“ automatisieren und Aussprachetraining in eine optimierte Debugging-Sitzung verwandeln.
Wir haben die App mit zwei verschiedenen Modi entwickelt, die als Ihre objektive Feedback-Schleife fungieren:
- Nativer Modus: Dieser nutzt den internen Android SpeechRecognizer. Betrachten Sie dies als einen strengen „Compiler“. Er kümmert sich nicht um Ihre Gefühle. Wenn Ihre Aussprache eines bestimmten Phonems falsch ist, transkribiert der Erkenner das falsche Wort. Er zwingt Sie, deutlich genug zu sprechen, damit eine Maschine es versteht – wenn die KI es nicht parsen kann, wird es ein Mensch wahrscheinlich auch nicht können.
- API-Modus: Für eine tiefere Analyse nutzt dieser Modus Backend-Transkriptionsdienste (wie Whisper), um Nuancen zu erfassen.
Anstatt Audiodateien selbst zu verwalten, führt DialogoVivo die Schleife für Sie aus:
- Das Szenario: Sie betreten ein Rollenspiel (z. B. „Kaffee bestellen“).
- Der Input: Die KI spricht einen Muttersprachler-Satz.
- Der Output: Sie antworten. Die App nimmt Sie sofort auf und transkribiert Sie.
- Das Fehlerprotokoll: Wenn Sie ein Wort so falsch aussprechen, dass sich die Bedeutung ändert, markiert der Validierungs-Agent dies sofort und zeigt Ihnen genau, was der „Zuhörer“ gehört hat im Vergleich zu dem, was Sie sagen wollten.
Hören Sie auf, fehlerhaften Code zu deployen
Sie brauchen keinen „perfekten“ Akzent, aber Sie brauchen klare, ausführbare Sprache. Wenn Sie es leid sind, missverstanden zu werden, müssen Sie aufhören, Ihren Ohren zu trauen, und anfangen, den Daten zu trauen.
Sie können die manuelle Shadowing-Technik heute mit jedem Podcast ausprobieren. Oder, wenn Sie eine automatisierte Sandbox zum Testen Ihrer Aussprache wollen, bevor Sie mit echten Menschen sprechen, können Sie DialogoVivo auf Android herunterladen.
Behandeln Sie Ihre Sprache wie Code: Auditieren Sie sie, debuggen Sie sie und deployen Sie sie dann mit Zuversicht.