
Technika Shadowing (Cieniowanie) to intensywne ćwiczenie wymowy, w którym słuchasz rodzimego użytkownika języka i powtarzasz za nim na głos z opóźnieniem 0,5 sekundy — w efekcie „będąc cieniem” mówcy. W przeciwieństwie do standardowego powtarzania (słuchaj, pauza, powtórz), shadowing zmusza Twój mózg do przetwarzania intonacji, szybkości i rytmu w czasie rzeczywistym. Jednak, aby ta technika faktycznie poprawiła Twój akcent, musisz uwzględnić „Diff Check” — pętlę informacji zwrotnej z nagrywaniem, aby zidentyfikować, gdzie Twój wynik (output) odbiega od źródła.
Błąd „U mnie działa”
Wszyscy tam byliśmy. Ćwiczysz zdanie sam w swoim pokoju. Brzmi idealnie. Czujesz się pewnie. Potem mówisz to do rodzimego użytkownika języka, a on marszczy brwi. „Co?”
Właśnie doświadczyłeś klasycznej awarii wdrożenia (deployment failure). W inżynierii oprogramowania nazywamy to problemem „U mnie działa” (Works on My Machine). Kod działa dobrze w twoim lokalnym środowisku (twoja głowa), ale wysypuje się na produkcji (ucho słuchacza).
Dlaczego tak się dzieje? Wynika to z błędu poznawczego zwanego Pętlą Fonologiczną. Twój mózg jest agresywnym autokorektorem. Kiedy mówisz, twój mózg przewiduje dźwięk, który zamierzasz wydać, i „słyszy” tę intencję, odfiltrowując twoje rzeczywiste błędy. Dosłownie nie możesz usłyszeć własnego akcentu, ponieważ twoje wewnętrzne „testy jednostkowe” są stronnicze.
Aby naprawić swoją wymowę, musisz przestać polegać na swoich wewnętrznych czujnikach i zacząć patrzeć w logi błędów.
Algorytm Shadowing (Protokół ręczny)
Najskuteczniejszym sposobem na ominięcie Pętli Fonologicznej jest Shadowing. To nie jest tylko „powtarzanie za nauczycielem”. To zadanie przetwarzania synchronicznego. Oto algorytm poprawnej sesji Shadowing:
- Strumień wejściowy (Input Stream): Znajdź natywne nagranie (podcast, wiadomości lub dialog) z transkrypcją.
- Konfiguracja opóźnienia: Uruchom dźwięk. Nie czekaj, aż zdanie się skończy.
- Przetwarzanie: Zacznij mówić w momencie, gdy zaczyna się dźwięk, podążając około 0,5 sekundy za mówcą.
- Synchronizacja: Naśladuj muzykę, nie tylko słowa. Jeśli mówca przyspiesza, ty przyspieszasz. Jeśli podnosi ton, ty podnosisz swój.
Ostrzeżenie: Jest to kosztowne poznawczo. Zużywa dużą przepustowość umysłową. Ale to samo w sobie nie wystarczy. Nadal uruchamiasz kod bez sprawdzania wyników.
„Diff Check”: Dlaczego potrzebujesz pętli zwrotnej
Badania nad hipotezą zauważania (Noticing Hypothesis) sugerują, że uczący się poprawiają błędy tylko wtedy, gdy świadomie zauważają lukę między swoim wynikiem a docelowym wkładem. Jeśli robisz shadowing bez nagrywania się, piszesz kod bez kompilatora. Czujesz się produktywnie, ale prawdopodobnie utrwalasz błędy (bugi).
Aby skutecznie debugować swoją wymowę, musisz wykonać Diff Check:
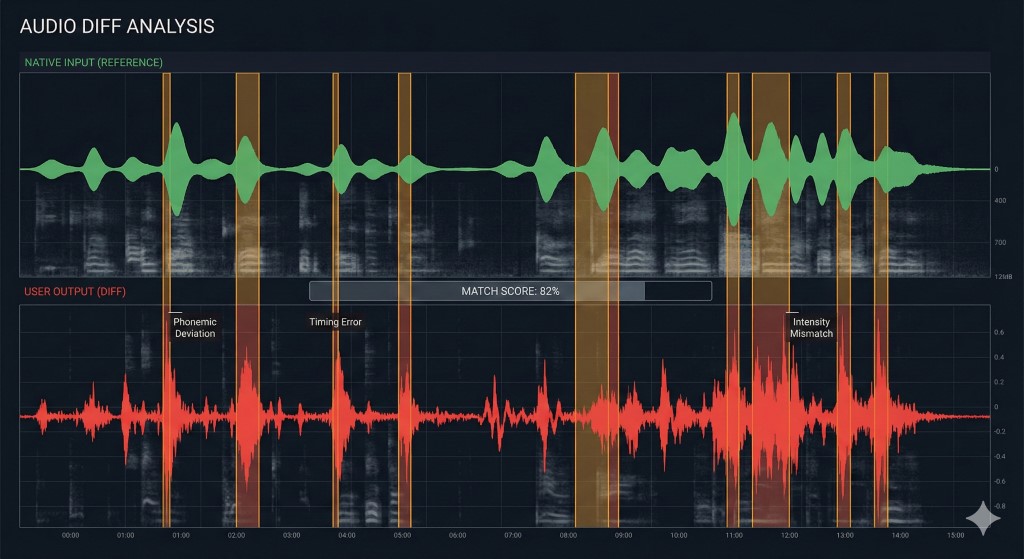
| Krok | Akcja | Odpowiednik „Inżynierski” |
|---|---|---|
| 1. Nagraj | Nagraj swój głos podczas shadowingu. | > capture logs |
| 2. Nałóż | Odsłuchaj swoje nagranie natychmiast po oryginale. | > git diff |
| 3. Zidentyfikuj | Zaznacz dokładnie, gdzie Twój rytm lub samogłoski odbiegały od normy. | > bug triage |
| 4. Łatka (Patch) | Powtarzaj konkretny segment, aż „diff” wyniesie zero. | > hotfix |
Powiązane lektury: Jeśli okaże się, że Twoje błędy są raczej gramatyczne niż fonetyczne, zapoznaj się z naszym przewodnikiem po Refaktoryzacji Gramatyki, aby naprawić skamieniałe błędy składniowe.
Automatyzacja debugera z DialogoVivo
Powyższy protokół ręczny jest skuteczny, ale żmudny. Ustawianie urządzeń nagrywających, pauzowanie dźwięku i przewijanie dodaje ogromnego tarcia. Kiedy tarcie jest duże, przestajesz ćwiczyć.
Dlatego stworzyliśmy DialogoVivo. Chcieliśmy zautomatyzować „Diff Check” i zamienić praktykę wymowy w usprawnioną sesję debugowania.
Zaprojektowaliśmy aplikację z dwoma różnymi trybami, które działają jako Twoja obiektywna pętla informacji zwrotnej:
- Tryb natywny: Wykorzystuje wewnętrzny SpeechRecognizer systemu Android. Pomyśl o tym jak o surowym „Kompilatorze”. Nie dba o Twoje uczucia. Jeśli Twoja wymowa konkretnego fonemu jest błędna, rozpoznawacz przepisze niewłaściwe słowo. Zmusza Cię to do mówienia wystarczająco wyraźnie, aby maszyna to zrozumiała — jeśli AI nie może tego przeanalizować, człowiek prawdopodobnie też nie.
- Tryb API: Do głębszej analizy ten tryb wykorzystuje backendowe usługi transkrypcji (takie jak Whisper), aby wychwycić niuanse.
Zamiast zarządzać plikami audio samodzielnie, DialogoVivo uruchamia pętlę za Ciebie:
- Scenariusz: Wchodzisz w odgrywanie ról (np. „Zamawianie kawy”).
- Wejście: AI wypowiada zdanie natywne.
- Wyjście: Odpowiadasz. Aplikacja natychmiast Cię nagrywa i transkrybuje.
- Log błędów: Jeśli wymówisz słowo tak źle, że zmieni ono znaczenie, Agent Walidacji natychmiast to oflaguje, pokazując dokładnie, co „usłyszał” słuchacz w porównaniu z tym, co chciałeś powiedzieć.
Przestań wdrażać zbugowany kod
Nie musisz mieć „idealnego” akcentu, ale potrzebujesz czystej, wykonywalnej mowy. Jeśli jesteś zmęczony byciem niezrozumianym, musisz przestać ufać swoim uszom i zacząć ufać danym.
Możesz wypróbować ręczną technikę Shadowing już dziś z dowolnym podcastem. Lub, jeśli chcesz zautomatyzowanej piaskownicy do testowania wymowy przed rozmową z prawdziwymi ludźmi, możesz pobrać DialogoVivo na Androida.
Traktuj swoją mowę jak kod: audytuj ją, debuguj, a następnie wdrażaj z pewnością siebie.