
A Técnica de Shadowing (Sombreamento) é um exercício de pronúncia de alta intensidade onde você ouve a fala nativa e a repete em voz alta com um atraso de 0,5 segundo — efetivamente fazendo uma "sombra" do falante. Ao contrário da repetição padrão (ouvir, pausar, repetir), o shadowing força seu cérebro a processar a entonação, a velocidade e o ritmo em tempo real. No entanto, para que essa técnica realmente melhore seu sotaque, você deve incluir um "Diff Check" — um loop de feedback de gravação para identificar onde sua saída se desvia da fonte.
A Falácia "Funciona na Minha Máquina"
Todos nós já passamos por isso. Você pratica uma frase sozinho no seu quarto. Soa perfeito. Você se sente confiante. Então, você diz para um falante nativo e ele franze a testa. "O quê?"
Você acabou de experimentar uma falha clássica de implantação (deployment failure). Na engenharia de software, chamamos isso de problema "Funciona na Minha Máquina" (Works on My Machine). O código roda bem no seu ambiente local (sua cabeça), mas trava em produção (o ouvido do ouvinte).
Por que isso acontece? É devido a um viés cognitivo chamado Loop Fonológico. Seu cérebro é um corretor automático agressivo. Quando você fala, seu cérebro antecipa o som que você pretende fazer e "ouve" essa intenção, filtrando seus erros reais. Você literalmente não consegue ouvir seu próprio sotaque porque seus "testes unitários" internos são tendenciosos.
Para consertar sua pronúncia, você precisa parar de confiar em seus sensores internos e começar a olhar os logs de erro.
O Algoritmo de Shadowing (Protocolo Manual)
A maneira mais eficaz de contornar o Loop Fonológico é o Shadowing. Isso não é apenas "repetir depois do professor". É uma tarefa de processamento síncrono. Aqui está o algoritmo para uma sessão de Shadowing adequada:
- Fluxo de Entrada (Input Stream): Encontre áudio nativo (um podcast, clipe de notícias ou diálogo) com uma transcrição.
- Configuração de Latência: Inicie o áudio. Não espere a frase terminar.
- Processamento: Comece a falar no momento em que o áudio começar, ficando cerca de 0,5 segundo atrás do falante.
- Sincronização: Imite a música, não apenas as palavras. Se o falante acelerar, você acelera. Se ele aumentar o tom, você aumenta o seu.
Aviso: Isso é cognitivamente custoso. Consome alta largura de banda mental. Mas isso por si só não é suficiente. Você ainda está executando o código sem verificar a saída.
O "Diff Check": Por que você precisa de um loop de feedback
Pesquisas sobre a Hipótese de Notação (Noticing Hypothesis) sugerem que os alunos só corrigem erros quando percebem conscientemente a lacuna entre sua saída e a entrada alvo. Se você faz shadowing sem se gravar, está escrevendo código sem um compilador. Você se sente produtivo, mas provavelmente está reforçando bugs.
Para depurar sua pronúncia efetivamente, você deve realizar um Diff Check:
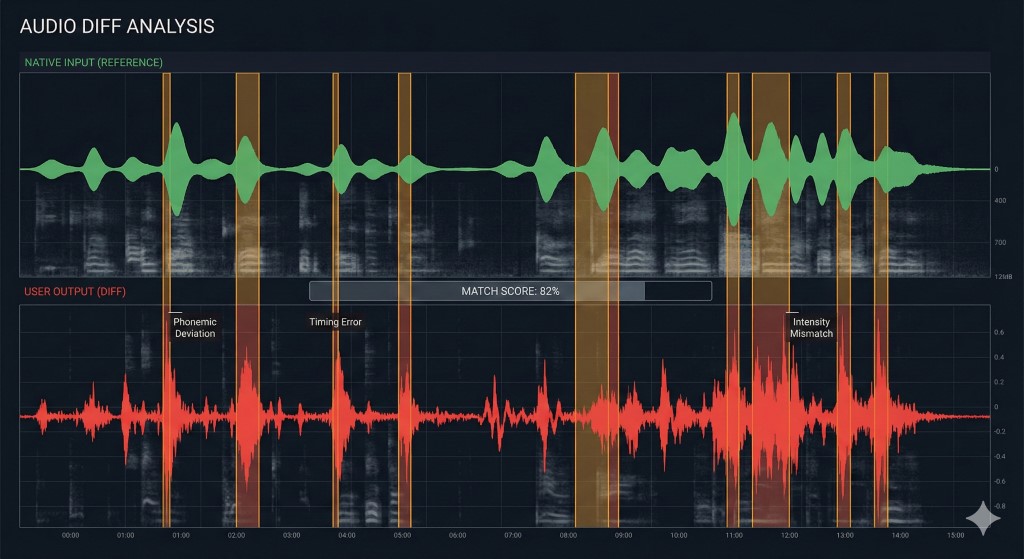
| Passo | Ação | Equivalente de "Engenharia" |
|---|---|---|
| 1. Gravar | Grave sua voz enquanto faz shadowing do áudio nativo. | > capture logs |
| 2. Sobrepor | Ouça sua gravação imediatamente após o áudio nativo. | > git diff |
| 3. Identificar | Marque exatamente onde seu ritmo ou sons vocálicos se desviaram. | > bug triage |
| 4. Patch | Repita o segmento específico até que o "diff" seja zero. | > hotfix |
Leitura Relacionada: Se você descobrir que seus erros são gramaticais em vez de fonéticos, confira nosso guia sobre Refatoração da Sua Gramática para corrigir erros de sintaxe fossilizados.
Automatizando o Depurador com DialogoVivo
O protocolo manual acima é eficaz, mas é tedioso. Configurar dispositivos de gravação, pausar áudio e percorrer linhas do tempo adiciona um atrito massivo. Quando o atrito é alto, você para de praticar.
É por isso que construímos o DialogoVivo. Queríamos automatizar o "Diff Check" e transformar a prática de pronúncia em uma sessão de depuração otimizada.
Projetamos o aplicativo com dois modos distintos para atuar como seu loop de feedback objetivo:
- Modo Nativo: Utiliza o SpeechRecognizer interno do sistema operacional Android. Pense nisso como um "Compilador" rigoroso. Ele não se importa com seus sentimentos. Se sua pronúncia de um fonema específico estiver errada, o reconhecedor transcreverá a palavra errada. Isso força você a falar com clareza suficiente para que uma máquina entenda — se a IA não consegue analisar, um humano provavelmente também não conseguirá.
- Modo API: Para uma análise mais profunda, este modo usa serviços de transcrição de backend (como Whisper) para capturar nuances.
Em vez de gerenciar arquivos de áudio você mesmo, o DialogoVivo executa o loop para você:
- O Cenário: Você entra em uma encenação (por exemplo, "Pedindo Café").
- A Entrada: A IA fala uma frase nativa.
- A Saída: Você responde. O aplicativo grava e transcreve você instantaneamente.
- O Log de Erros: Se você pronunciar uma palavra tão mal que mude o significado, o Agente de Validação a sinaliza imediatamente, mostrando exatamente o que o "ouvinte" ouviu versus o que você pretendia dizer.
Pare de Implantar Código com Bugs
Você não precisa ter um sotaque "perfeito", mas precisa de uma fala clara e executável. Se você está cansado de ser mal interpretado, precisa parar de confiar em seus ouvidos e começar a confiar nos dados.
Você pode tentar a técnica manual de Shadowing hoje com qualquer podcast. Ou, se quiser um sandbox automatizado para testar sua pronúncia antes de falar com humanos reais, pode baixar o DialogoVivo no Android.
Trate sua fala como código: audite, depure e depois implante com confiança.